Analysis of Imputation Methods for Missing Not at Random (MNAR) Data: A Comparative Study of Air Pollution Data in Bangkok, Thailand
DOI:
https://doi.org/10.59796/jcst.V16N2.2026.187Keywords:
air pollution, Policy recommendations, imputation; long short-term memory (LSTM), missing values, missing not at random (MNAR), random forest (RF)Abstract
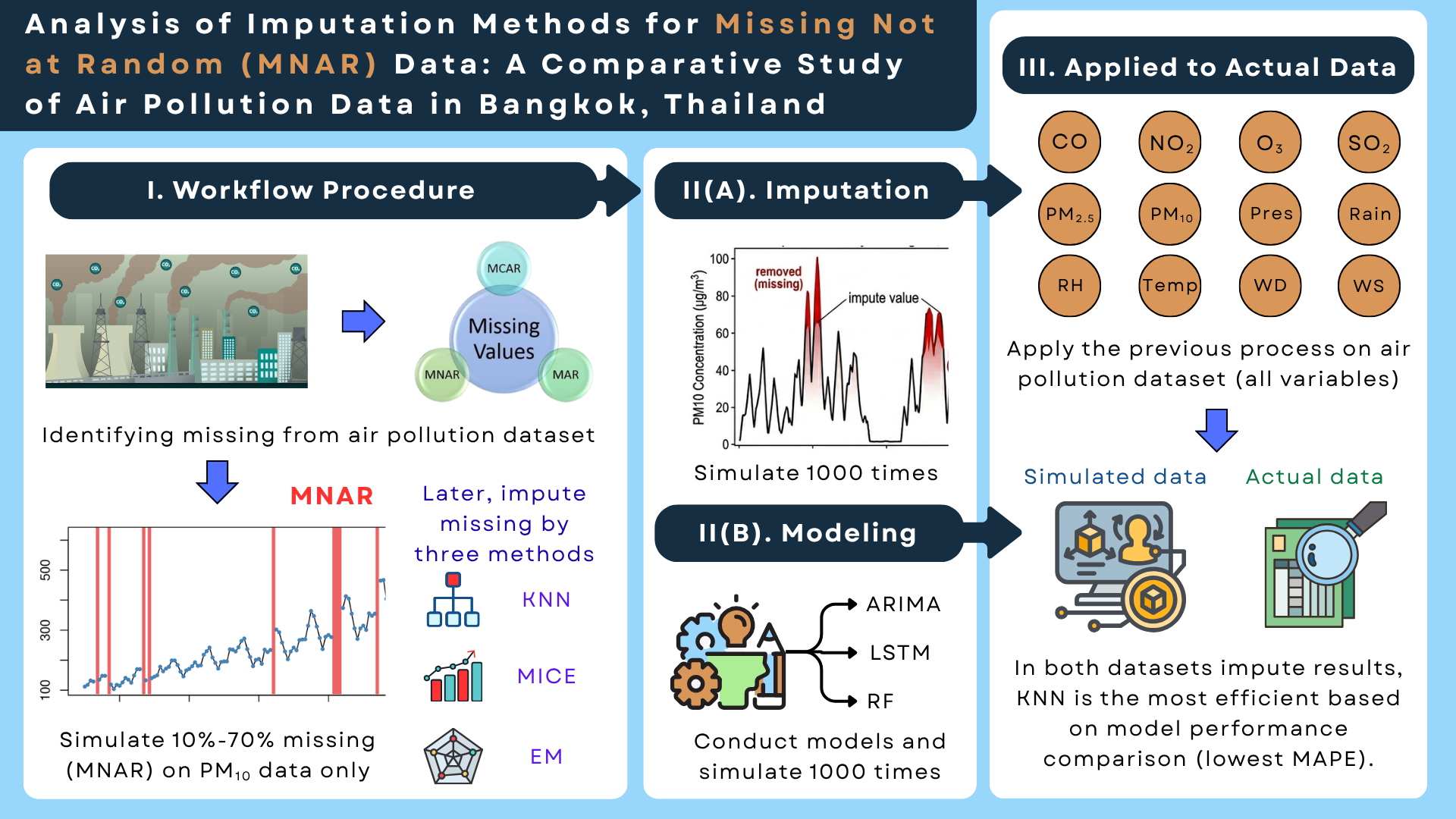
Environmental datasets are often large in scale and frequently contain missing observations due to interruptions. Addressing these missing values is essential for ensuring the reliability of subsequent analyses. In many practical cases, missingness depends on the unobserved values or the technical issues themselves. This missing status is called Missing Not at Random (MNAR), which remains one of the most challenging missing data mechanisms. This study investigates the MNAR pattern in an air pollution dataset from Bangkok, Thailand. A simulation framework used the variable as the target variable for random missing with MNAR patterns at varying rates. The methods used for missing-value imputation were K-Nearest Neighbors (KNN), Multiple Imputation by Chained Equations (MICE), and the Expectation Maximization (EM) algorithm. Imputation accuracy was evaluated using Root Mean Square Error (RMSE). Furthermore, imputation efficiency was tested by conducting ARIMA, LSTM, and RF forecasting models, and model performance was evaluated using Mean Absolute Percentage Error (MAPE). The simulation results showed that KNN consistently achieved the lowest RMSE (1.66-2.68) for missing-value imputation at 10%-70% missing rates. In addition, KNN-based models showed better performance in ARIMA, and the LSTM models achieved the lowest MAPE (2.31–2.46) across all missing rates, while EM-based models excel at the RF model better than KNN. When applied to the actual air pollution dataset, KNN-based models also performed most effectively for variables containing MNAR. However, for other missingness types, MICE- and EM-based models outperformed KNN-based models. Overall, this study highlights practical and efficient approaches for handling MNAR missingness in environmental datasets and provides insights that can help future researchers better recognize, manage, and mitigate MNAR-related issues in real-world data collection.
References
Agiwal, V., & Chaudhuri, S. (2024). Methods and implications of addressing missing data in health-care research. Current Medical Issues, 22(1), 60-62. https://doi.org/10.4103/cmi.cmi_121_23
Ahmad, M., Manjantrarat, T., Rattanawongsa, W., Muensri, P., Saenmuangchin, R., Klamchuen, A., ... & Panyametheekul, S. (2022). Chemical composition, sources, and health risk assessment of PM2.5 and PM10 in urban sites of Bangkok, Thailand. International Journal of Environmental Research and Public Health, 19(21), Article 14281. https://doi.org/10.3390/ijerph192114281
Ahn, H., Sun, K., & Kim, K. P. (2022). Comparison of missing data imputation methods in time series forecasting. Computers, Materials, & Continua, 70(1), 767-779. http://doi.org/10.32604/cmc.2022.019369
Ali, J., Khan, R., Ahmad, N., & Maqsood, I. (2012). Random forests and decision trees. International Journal of Computer Science Issues (IJCSI), 9(5), 272-278.
Allison, P. D. (2009). Missing data. The SAGE Handbook of Quantitative Methods in Psychology, 23, 72-89. https://doi.org/10.4135/9780857020994.n4
Alruhaymi, A. Z., & Kim, C. J. (2021). Why can multiple imputations and how (mice) algorithm work?. Open Journal of Statistics, 11(5), 759-777. https://doi.org/10.4236/ojs.2021.115045
Alruhaymi, A. Z., Kim, C. J., Alruhaymi, A. Z., & Kim, C. J. (2021). Study on the missing data mechanisms and imputation methods. Open Journal of Statistics, 11(4), 477-492. https://doi.org/10.4236/ojs.2021.114030
Ban, W., & Shen, L. (2022). PM2.5 prediction based on the CEEMDAN algorithm and a machine learning hybrid model. Sustainability, 14(23), Article 16128. https://doi.org/10.3390/su142316128
Bartholomew, D. J. (1971). Time series analysis forecasting and control. Journal of the Operational Research Society, 22(2), 199–201. https://doi.org/10.1057/jors.1971.52
Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5-32. https://doi.org/10.1023/A:1010933404324
Cheewinsiriwat, P., Duangyiwa, C., Sukitpaneenit, M., & Stettler, M. E. (2022). Influence of land use and meteorological factors on PM2.5 and PM10 concentrations in Bangkok, Thailand. Sustainability, 14(9), Article 5367. https://doi.org/10.3390/su14095367
Chhabra, G. (2024). Handling Missing Data through Artificial Neural Network. Communications on Applied Nonlinear Analysis, 31, 677-684. https://doi.org/10.52783/cana.v31.1429
Cumming, G., & Finch, S. (2005). Inference by eye: confidence intervals and how to read pictures of data. American Psychologist, 60(2), 170-180. https://psycnet.apa.org/doi/10.1037/0003-066X.60.2.170
Fadlil, A., & Herman, P. M. D. (2022). K nearest neighbor imputation performance on missing value data graduate user satisfaction. Jurnal RESTI (Rekayasa Sistem dan Teknologi Informasi), 6(4), 570-576. https://doi.org/10.29207/resti.v6i4.4173
Heymans, M. W., & Twisk, J. W. (2022). Handling missing data in clinical research. Journal of Clinical Epidemiology, 151, 185-188. https://doi.org/10.1016/j.jclinepi.2022.08.016
Hosamane, S. N., Prashanth, K. S., & Virupakshi, A. S. (2020). Assessment and prediction of PM10 concentration using ARIMA. Journal of Physics: Conference Series, 1706(1), Article 012132. https://doi.org/10.1088/1742-6596/1706/1/012132
Hyndman, R. J. (2001). ARIMA processes. Datajobs: Data Science Knowledge. Retrieved from https://www.researchgate.net/publication/222105783_ARIMA_processes
Iamtrakul, P., Padon, A., & Chayphong, S. (2024). Quantifying the impact of urban growth on urban surface heat islands in the Bangkok Metropolitan Region, Thailand. Atmosphere, 15(1), Article 100. https://doi.org/10.3390/atmos15010100
Joel, L. O., Doorsamy, W., & Paul, B. S. (2022). A review of missing data handling techniques for machine learning. International Journal of Innovative Technology and Interdisciplinary Sciences, 5(3), 971-1005. https://doi.org/10.15157/IJITIS.2022.5.3.971-1005
Junger, W. L., & De Leon, A. P. (2015). Imputation of missing data in time series for air pollutants. Atmospheric Environment, 102, 96-104. https://doi.org/10.1016/j.atmosenv.2014.11.049
Kang, H. (2013). The prevention and handling of the missing data. Korean Journal of Anesthesiology, 64(5), 402-406. https://doi.org/10.4097/kjae.2013.64.5.402
Karnati, H., Soma, A., Alam, A., & Kalaavathi, B. (2025). Comprehensive analysis of various imputation and forecasting models for predicting PM2.5 pollutant in Delhi. Neural Computing and Applications, 37(17), 11441-11458. https://doi.org/10.1007/s00521-025-11047-2
Kim, S., & Kim, H. (2016). A new metric of absolute percentage error for intermittent demand forecasts. International Journal of Forecasting, 32(3), 669-679. https://doi.org/10.1016/j.ijforecast.2015.12.003
Laqueur, H. S., Shev, A. B., & Kagawa, R. M. (2022). SuperMICE: An ensemble machine learning approach to multiple imputation by chained equations. American Journal of Epidemiology, 191(3), 516-525. https://doi.org/10.1093/aje/kwab271
Li, J., Guo, S., Ma, R., He, J., Zhang, X., Rui, D., ... & Guo, H. (2024). Comparison of the effects of imputation methods for missing data in predictive modelling of cohort study datasets. BMC Medical Research Methodology, 24(1), Article 41. https://doi.org/10.1186/s12874-024-02173-x
Lim, A., Owusu, B. A., Thongrod, T., Khurram, H., Pongsiri, N., Ingviya, T., & Buya, S. (2025). Trend and association between particulate matters and meteorological factors: A prospect for prediction of PM2.5 in Southern Thailand. Polish Journal of Environmental Studies, 34(5), 5215-5223. https://doi.org/10.15244/pjoes/190787
Lin, T. H. (2010). A comparison of multiple imputation with EM algorithm and MCMC method for quality of life missing data. Quality & Quantity, 44(2), 277-287. https://doi.org/10.1007/s11135-008-9196-5
Morris, T. P., White, I. R., & Royston, P. (2014). Tuning multiple imputation by predictive mean matching and local residual draws. BMC Medical Research Methodology, 14(1), Article 75. https://doi.org/10.1186/1471-2288-14-75
Mukherjee, K., Gunsoy, N. B., Kristy, R. M., Cappelleri, J. C., Roydhouse, J., Stephenson, J. J., ... & Di Tanna, G. L. (2023). Handling missing data in health economics and outcomes research (HEOR): A systematic review and practical recommendations. Pharmacoeconomics, 41(12), 1589-1601. https://doi.org/10.1007/s40273-023-01297-0
Nguyen, G. T. H., La, L. T., Hoang-Cong, H., & Le, A. H. (2024). An exploration of meteorological effects on PM2.5 air quality in several provinces and cities in Vietnam. Journal of Environmental Sciences, 145, 139-151. https://doi.org/10.1016/j.jes.2023.07.020
Nourmohammad, E., & Rashidi, Y. (2025). Ground data analysis for PM2.5 Prediction using predictive modeling techniques. Journal of Air Pollution and Health, 10(1), 61-82. https://doi.org/10.18502/japh.v10i1.18095
Pan, X. (2024). The comparison between random forest and LSTM models based on the gold price prediction. Advances in Economics Management and Political Sciences, 94(1), 102-108. https://doi.org/10.54254/2754-1169/94/2024ox0150
Pereira, R. C., Abreu, P. H., Rodrigues, P. P., & Figueiredo, M. A. (2024). Imputation of data missing not at random: Artificial generation and benchmark analysis. Expert Systems with Applications, 249(B), Article 123654. https://doi.org/10.1016/j.eswa.2024.123654
Ponsawansong, P., Prapamontol, T., Rerkasem, K., Chantara, S., Tantrakarnapa, K., Kawichai, S., ... & Zhang, Y. (2023). Sources of PM2.5 oxidative potential during haze and non-haze seasons in Chiang Mai, Thailand. Aerosol and Air Quality Research, 23(10), Article 230030. https://doi.org/10.4209/aaqr.230030
Ranganathan, P., & Hunsberger, S. (2024). Handling missing data in research. Perspectives in Clinical Research, 15(2), 99-101. https://doi.org/10.4103/picr.picr_38_24
Rubin, D. B. (1976). Inference and missing data. Biometrika, 63(3), 581-592. https://doi.org/10.1093/biomet/63.3.581
Song, J., Gao, Y., Yin, P., Li, Y., Li, Y., Zhang, J., ... & Pi, H. (2021). The random forest model has the best accuracy among the four pressure ulcer prediction models using machine learning algorithms. Risk Management and Healthcare Policy, 14, 1175-1187. https://doi.org/10.2147/RMHP.S297838
Takale, G., Wattamwar, A., Saipatwar, S., Saindane, H., & Patil, T. B. (2024). Comparative analysis of LSTM, RNN, CNN and MLP machine learning algorithms for stock value prediction. Journal of Firewall Software and Networking, 2(1), 1-10. https://doi.org/10.48001/jofsn.2024.211-10
Tayman, J., & Swanson, D. A. (1999). On the validity of MAPE as a measure of population forecast accuracy. Population Research and Policy Review, 18(4), 299-322. https://doi.org/10.1023/A:1006166418051
Troyanskaya, O., Cantor, M., Sherlock, G., Brown, P., Hastie, T., Tibshirani, R., ... & Altman, R. B. (2001). Missing value estimation methods for DNA microarrays. Bioinformatics, 17(6), 520-525. https://doi.org/10.1093/bioinformatics/17.6.520
Utama, A. B. P., Wibawa, A. P., Handayani, A. N., Irianto, W. S. G., & Nyoto, A. (2024). Improving time-series forecasting performance using imputation techniques in deep learning [Conference presentation]. 2024 International Conference on Smart Computing, IoT and Machine Learning (SIML). IEEE, Surakarta, Indonesia. https://doi.org/10.1109/SIML61815.2024.10578273
Wang, W. (2024). Comparative analysis of ARIMA, random forest, and LSTM models for Mercedes-Benz stock price prediction. Advances in Economics, Management and Political Sciences, 134(1), 1-8. https://doi.org/10.54254/2754-1169/2024.18718
Downloads
Published
How to Cite
Issue
Section
Categories
License
Copyright (c) 2026 Journal of Current Science and Technology

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.