An Explainable Approach to Sentiment Analysis of Thai Hotel Reviews Using a Fine-Tuned Language Model and SHAP
DOI:
https://doi.org/10.59796/jcst.V15N4.2025.149Keywords:
WangchanBERTa, Thai language model, sentiment analysis, SHAP, hotel reviews, low-resource languagesAbstract
Sentiment analysis plays a pivotal role in the hotel industry, where user-generated reviews significantly influence customer decisions. However, traditional machine learning (ML) methods often struggle with the linguistic nuances of languages such as Thai. This study investigates the effectiveness of fine-tuning WangchanBERTa, a monolingual Thai large language model (LLM), for sentiment classification of hotel reviews from Bangkok. The model's performance was compared with ML algorithms, including extreme gradient boosting (XGBoost), support vector machines (SVM), logistic regression (LR), and multinomial naïve Bayes (MNB). The comparison highlights the advantages of deep contextual understanding enabled by transformer-based architecture. To improve interpretability, Shapley Additive Explanation (SHAP) was applied to the best-performing model to analyze feature importance. The results show that the fine-tuned LLM outperformed all ML models, achieving over 92% across all evaluation metrics (accuracy, precision, recall, and F1-score). SHAP analysis enhanced transparency by revealing sentiment drivers relevant to the hotel domain. This study contributes to the advancement of natural language processing (NLP) for low-resource languages by demonstrating the effectiveness of domain-specific fine-tuning combined with explainable artificial intelligence (XAI) in practical applications.
References
Almuayqil, S. N., Humayun, M., Jhanjhi, N. Z., Almufareh, M. F., & Khan, N. A. (2022). Enhancing sentiment analysis via random majority under-sampling with reduced time complexity for classifying tweet reviews. Electronics, 11(21), Article 3624. https://doi.org/10.3390/electronics11213624
Arreerard, R., Mander, S., & Piao, S. (2022). Survey on Thai NLP language resources and tools [Conference presentation]. Proceedings of the Thirteenth Language Resources and Evaluation Conference, Marseille, France. https://aclanthology.org/2022.lrec-1.697/
Bimagambetova, Z., Rakhymzhanov, D., Jaxylykova, A., & Pak, A. (2023). Evaluating large language models for sentence augmentation in low-resource languages: A case study on Kazakh [Conference presentation]. 2023 19th International Asian School-Seminar on Optimization Problems of Complex Systems (OPCS), Moscow, Russia. https://doi.org/10.1109/OPCS59592.2023.10275753
Büyük, O. (2024). A comprehensive evaluation of large language models for turkish abstractive dialogue summarization. IEEE Access, 12, 124391–124401. https://doi.org/10.1109/ACCESS.2024.3454342
Chaisen, T., Charoenkwan, P., Kim, C. G., & Thiengburanathum, P. (2024). A zero-shot interpretable framework for sentiment polarity extraction. IEEE Access, 12, 10586–10607. https://doi.org/10.1109/ACCESS.2023.3322103
Conneau, A., Khandelwal, K., Goyal, N., Chaudhary, V., Wenzek, G., Guzmán, F., ... & Stoyanov, V. (2020). Unsupervised cross-lingual representation learning at scale [Conference presentation]. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online. https://doi.org/10.18653/v1/2020.acl-main.747
Devlin, J. (2019). Bert/multilingual.md. Retrieved from https://github.com/google-research/bert/blob/master/multilingual.md#list-of-languages
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding [Conference presentation]. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, United States. https://doi.org/10.18653/v1/N19-1423
Gatchalee, P., Waijanya, S., & Promrit, N. (2023). Thai text classification experiment using CNN and transformer models for timely-timeless content marketing. ICIC Express Letters, 17(01), 91–101. https://doi.org/10.24507/icicel.17.01.91
Golchubian, A., Marques, O., & Nojoumian, M. (2021). Photo quality classification using deep learning. Multimedia Tools and Applications, 80(14), 22193–22208. https://doi.org/10.1007/s11042-021-10766-7
Goyal, N., Du, J., Ott, M., Anantharaman, G., & Conneau, A. (2021). Larger-scale transformers for multilingual masked language modeling [Conference presentation]. Proceedings of the 6th Workshop on Representation Learning for NLP (RepL4NLP-2021), Bangkok, Thailand. https://doi.org/10.18653/v1/2021.repl4nlp-1.4
Han, J., Yang, T., Zhang, C., & Jiang, H. (2024). Fine-tuning large language models for the electric power industry with specialized Chinese electric power corpora [Conference presentation]. 2024 5th International Conference on Computers and Artificial Intelligence Technology (CAIT), Zhejiang, China. https://doi.org/10.1109/CAIT64506.2024.10963259
Harnmetta, P., & Samanchuen, T. (2022). Sentiment analysis of Thai stock reviews using transformer models [Conference presentation]. 2022 19th International Joint Conference on Computer Science and Software Engineering (JCSSE), Bangkok, Thailand. https://doi.org/10.1109/JCSSE54890.2022.9836278
Howard, J., & Ruder, S. (2018). Universal language model fine-tuning for text classification [Conference presentation]. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia. https://doi.org/10.18653/v1/P18-1031
Indira Kumar, A. K., Sthanusubramoniani, G., Gupta, D., Nair, A. R., Alotaibi, Y. A., & Zakariah, M. (2025). Multi-task detection of harmful content in code-mixed meme captions using large language models with zero-shot, few-shot, and fine-tuning approaches. Egyptian Informatics Journal, 30, Article 100683. https://doi.org/10.1016/j.eij.2025.100683
Kastrati, M., Imran, A. S., Hashmi, E., Kastrati, Z., Daudpota, S. M., & Biba, M. (2025). Unlocking language barriers: Assessing pre-trained large language models across multilingual tasks and unveiling the black box with explainable artificial intelligence. Engineering Applications of Artificial Intelligence, 149, Article 110136. https://doi.org/10.1016/j.engappai.2025.110136
Khamphakdee, N., & Seresangtakul, P. (2021a). A framework for constructing thai sentiment corpus using the cosine similarity technique [Conference presentation]. 2021 13th International Conference on Knowledge and Smart Technology (KST), Chonburi, Thailand. https://doi.org/10.1109/KST51265.2021.9415802
Khamphakdee, N., & Seresangtakul, P. (2021b). Sentiment analysis for Thai language in hotel domain using machine learning algorithms. Acta Informatica Pragensia, 10(2), 155-171. https://doi.org/10.18267/j.aip.155
Khamphakdee, N., & Seresangtakul, P. (2023). An efficient deep learning for Thai sentiment analysis. Data, 8(5), Article 90. https://doi.org/10.3390/data8050090
Khoboko, P. W., Marivate, V., & Sefara, J. (2025). Optimizing translation for low-resource languages: Efficient fine-tuning with custom prompt engineering in large language models. Machine Learning with Applications, 20, Article 100649. https://doi.org/10.1016/j.mlwa.2025.100649
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., ... & Stoyanov, V. (2019). RoBERTa: A robustly optimized bert pretraining approach (Version 1). arXiv, https://doi.org/10.48550/ARXIV.1907.11692
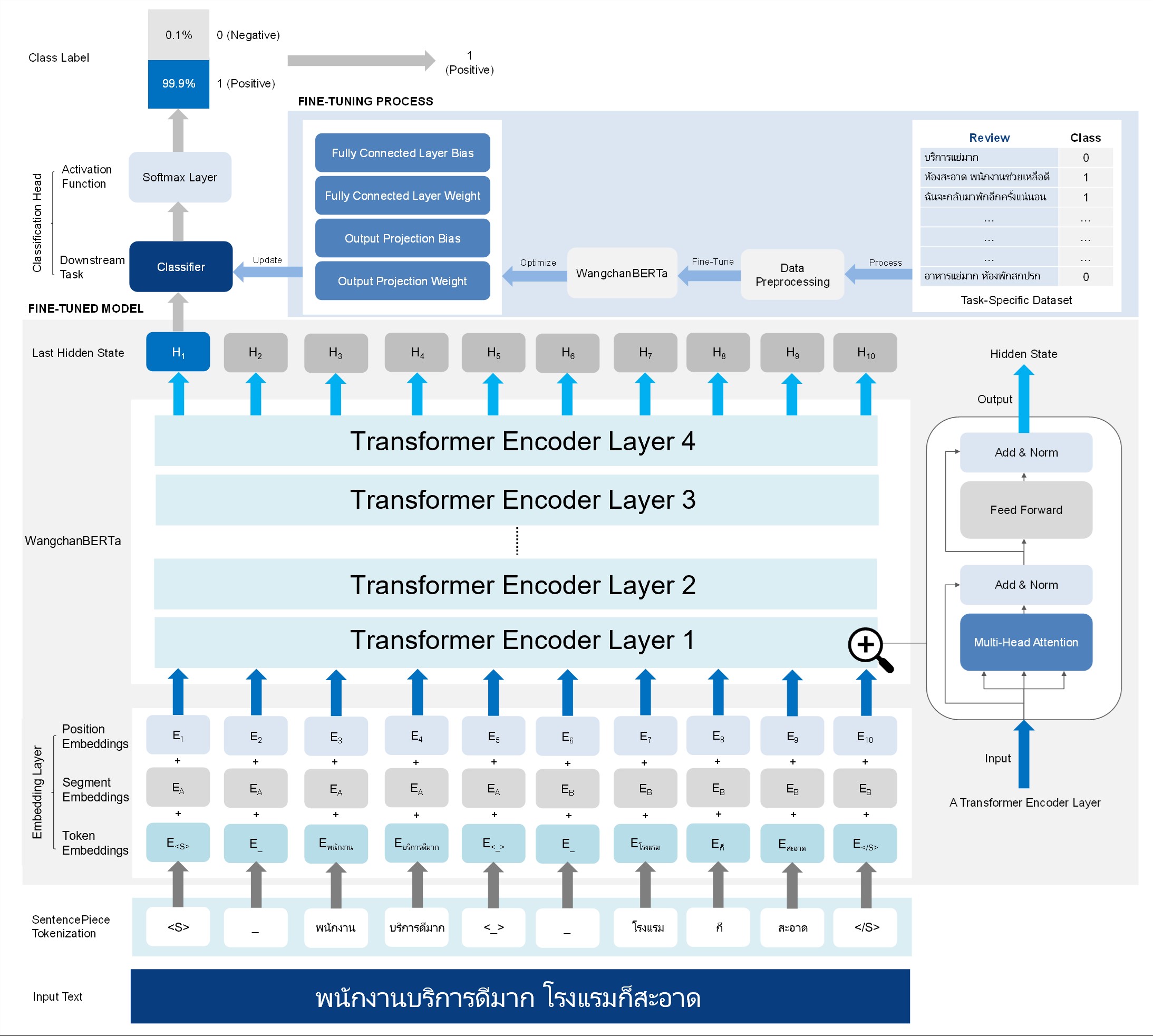
Lowphansirikul, L., Polpanumas, C., Jantrakulchai, N., & Nutanong, S. (2021). WangchanBERTa: pretraining transformer-based Thai language models (Version 2). arXiv, https://doi.org/10.48550/ARXIV.2101.09635
Ozkaya, I. (2023). Application of large language models to software engineering tasks: Opportunities, risks, and implications. IEEE Software, 40(3), 4–8. https://doi.org/10.1109/MS.2023.3248401
Peters, M., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep contextualized word representations [Conference presentation]. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, United States. https://doi.org/10.18653/v1/N18-1202
Phatthiyaphaibun, W., Chaovavanich, K., Polpanumas, C., Suriyawongkul, A., Lowphansirikul, L., & Pattarawat Chormai. (2020). PyThaiNLP/pythainlp: PyThaiNLP 2.1.4 (Version v2.1.4) [Computer software]. Zenodo. https://doi.org/10.5281/ZENODO.3659277
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving Language Understanding by Generative Pre-Training. OpenAI. Retrieved from https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
Saetia, C., Thonglong, A., Amornchaiteera, T., Chalothorn, T., Taerungruang, S., & Buabthong, P. (2024). Streamlining event extraction with a simplified annotation framework. Frontiers in Artificial Intelligence, 7, Article 1361483. https://doi.org/10.3389/frai.2024.1361483
Sanchan, N. (2024). Comparative study on automated reference summary generation using BERT models and ROUGE score assessment. Journal of Current Science and Technology, 14(2), Article 26. https://doi.org/10.59796/jcst.V14N2.2024.26
Simmachan, T., & Boonkrong, P. (2025). Effect of resampling techniques on machine learning models for classifying road accident severity in Thailand. Journal of Current Science and Technology, 15(2), Article 99. https://doi.org/10.59796/jcst.V15N2.2025.99
ThAIKeras. (2018). ThAIKeras/bert. Retrieved from https://github.com/ThAIKeras/bert
Thiengburanathum, P., & Charoenkwan, P. (2023). SETAR: Stacking ensemble learning for Thai sentiment analysis using RoBERTa and hybrid feature representation. IEEE Access, 11, 92822–92837. https://doi.org/10.1109/ACCESS.2023.3308951
Downloads
Published
How to Cite
Issue
Section
Categories
License
Copyright (c) 2025 Journal of Current Science and Technology

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.